
Cut MTTR with Automatic Root Cause Localization for AI & IT Systems
InsightFinder AI has introduced automatic root cause localization – a new capability that will significantly reduce the time and effort needed to solve production outages. Automatic root cause localization analyzes causal chains, giving monitoring teams for both AI models and IT systems a quick way to see what actions are most important – and where to put their attention and effort. With automatic root cause localization, monitoring teams can cut through the flurry of alerts that are fired off during an outage to zero in on the critical root cause – reducing Mean Time To Resolution (MTTR) and improving overall system performance.
Eliminate Alert Overload: Pinpoint Root Causes Instantly with AI
Too many notifications? Distributed enterprise IT systems are complex by definition – with servers, database, and middleware combining across on-prem and cloud deployments. Enterprise-scale AI models are similarly complex – with potential performance issues in both the models themselves and the underlying infrastructure that supports them.
When a system slowdown or failure occurs the monitoring team can face a cascade of notifications as the different components of the system reach their alerting thresholds. For monitoring teams, this creates an unwelcome distraction from the job-at-hand of finding the actual cause of the system failure.
From Alerts to Action: AI-Driven Root Cause Localization for IT & AI Models
To solve this problem, InsightFinder has introduced the industry’s first automatic root cause localization solution for complex distributed IT systems and enterprise-scale AI models. By analyzing causal chains, InsightFinder gives the monitoring team a quick way to see what actions are most important – and where to put their attention and effort.
Reduce Downtime with Automatic Root Cause Analysis for Complex Systems
Here’s how it works: during an outage, many components of a distributed system will experience abnormal behaviors such as slowdowns or failures. Observability tools will attempt to create the causal chain from each of these incidents, tracing back to a root cause. In a complex system, there may be hundreds of causal chains created, as the many different components of the system experience performance degradation. Automatic root cause localization assigns a root cause score – showing how many causal chains each root cause is in. This shows immediately where the monitoring team should put its effort.
Here’s an example: here at InsightFinder AI we had a production outage occur on Saturday, January 11th. Thanks to our own AI-driven root cause localization capability, our operation team quickly identified the top root cause as the instance down anomaly in one of the Cassandra database nodes (shown in the pullout window of the screenshot below).
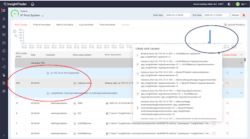
(Blue circle shows the system failure at 20:50 on Feb 11. Red circle shows the highest impact root cause)
More specifically, InsightFinder identified a node failure of our Cassandra distributed database (occurring at 20:40) as having a Root Cause Score of 305 – meaning that this anomaly appears as the root cause in 305 causal chains (circled in red). For the response team, the highest impact issue is clearly the Cassandra node failure. By moving to address this immediately, the on-call operations team saved themselves from spending many hours manually checking thousands of “out of memory” and “backoff and restart” alerts from many containers caused by this single database node failure. Instead, the team focused their efforts on fixing the highest impact problem to recover the system swiftly.
InsightFinder’s AI-Powered Root Cause Localization: Fix Outages Faster
By using InsightFinder’s automatic root cause localization capability, teams see the true root cause more quickly than with other systems. Actions are taken to fix the problem quickly, reducing MTTR and ensuring system reliability. (Automatic root cause localization is part of InsightFinder’s AI Observability and IT Observability platforms.)
To learn more about how InsightFinder can help your AI-driven observability programs, schedule a demo today.



