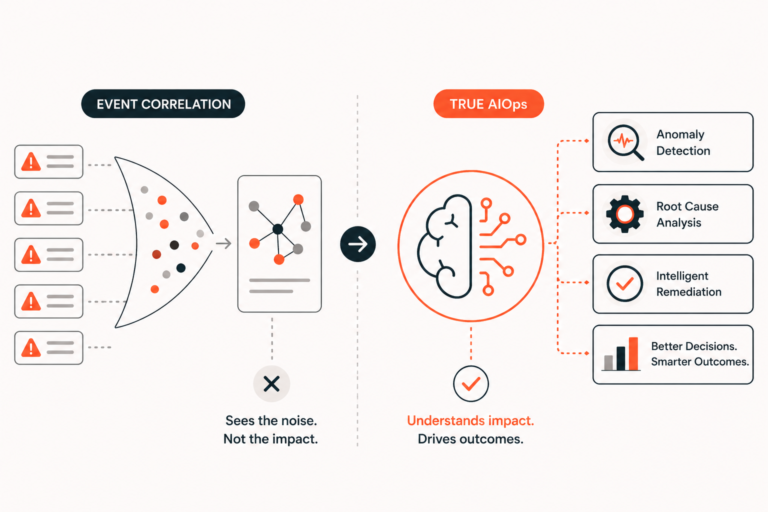
AIOps was supposed to make operations calmer. For many teams, it’s done the opposite in a quieter way. Alerts may be grouped, dashboards may look cleaner, and incident queues may appear more organized, but engineers still spend too much time asking the same painful question: where should we start?
That’s the problem at the center of our webinar, “Replacing Rule-Based AIOps with Predictive Reliability Workflows.” In it, we make a practical argument that many operations leaders already recognize: if an AIOps platform still depends on brittle rules, manual thresholds, and after-the-fact event correlation, it may reduce some alert noise, but it hasn’t fundamentally changed incident response.
Correlation has value. It can help teams see which symptoms appeared together and reduce the flood of redundant alerts during an outage. But correlation isn’t the same as understanding. Modern reliability teams need more than grouped events. They need earlier signals, causal context, and recommendations that fit the way incidents are actually managed.
Why Traditional AIOps Turns Into Rule Maintenance
The failure mode is familiar. A team buys an AIOps platform to reduce operational toil, then discovers that the platform itself requires constant care. Engineers tune thresholds, maintain correlation rules, suppress false positives, and revisit logic every time the architecture changes.
This isn’t because the team lacks discipline. It’s because rule-driven systems age poorly in environments that change quickly. Services move, dependencies evolve, deployments happen continuously, and infrastructure behavior changes as workloads shift. In AI-heavy environments, the picture gets even messier because reliability issues can originate in data pipelines, retrieval systems, model behavior, or application infrastructure.
Rules tend to describe yesterday’s system. Production rarely waits for those rules to catch up. Over time, the “AI” layer becomes another operational dependency, and on-call teams pay that tax during the worst possible moments.
Event Correlation Reduces Noise, But It Doesn’t Find Cause
Correlation answers a narrow question: which signals appeared around the same time? That question matters during an alert storm, but it doesn’t go far enough. An engineer responding at 2:00 a.m. doesn’t only need fewer alerts. Even Google suggests SREs need a their incidents.
A clustered set of events can still leave responders staring at symptoms. CPU saturation, API timeouts, queue depth, and latency may all move together, but only one part of that chain may explain how the incident started. Without causal context, teams still rely on intuition, tribal knowledge, and escalation.
That’s where correlation-heavy AIOps often plateaus. It makes the noise easier to see, but it doesn’t make the system easier to understand. The more meaningful test is whether the platform reduces the time it takes to form and validate a strong hypothesis.
A Retail Checkout Incident Shows the Gap
Consider a retail checkout service during a high-traffic window. Latency begins rising in one region, but error rates remain low. Database utilization looks normal. The first alerts come from application performance thresholds, followed by API gateway timeouts and thread pool saturation.
A correlation-based tool may group those events and identify them as part of one incident. That is useful, but it still points responders toward the loudest signals near the end of the failure chain. The real cause may have appeared earlier, before the system crossed an obvious threshold.
Maybe a deployment changed a retry policy. Those retries increased pressure on an internal dependency. A downstream queue started backing up slowly, then latency rose across checkout calls. By the time timeouts appeared, the system was already in a degraded state.
This pattern is common in distributed systems. The most visible symptom is often not the most useful clue. When teams start their investigation at the incident timestamp, they tend to chase effects. A better workflow looks back before the incident and asks what changed the system’s trajectory.
Predictive AIOps Needs Causal Context
Causal analysis changes the response motion. Instead of asking what fired together, it asks what likely influenced the degradation path. That distinction matters because incidents unfold over time, not as a flat pile of simultaneous events.
A more useful AIOps system surfaces likely precursors, ranks them by relevance, and shows the evidence trail behind recommendations. It helps responders see that a retry-policy change preceded queue growth, which preceded latency, which preceded timeouts. That kind of context doesn’t replace engineering judgment. It gives engineering judgment a better starting point.
This is also where “predictive reliability workflows” come into play. Prediction isn’t just about warning that something might break. It’s about detecting weak signals early enough to change the outcome and delivering those signals where teams can act on them.
Better AI Requires Better Inputs
Many AIOps tools operate from alerts and events as their main source of truth. That creates a hard ceiling. If the platform only sees what existing rules already decided was important, it inherits the blind spots of those rules.
Modern reliability requires richer evidence. Metrics, logs, traces, topology, deployment events, incidents, tickets, and runbook history all help explain how a system behaves. In AI and ML environments, teams may also need signals from model quality, drift, retrieval performance, feature pipelines, and inference behavior.
This is why observability maturity matters. Telemetry collection is a start. But the real power comes from preserving enough context for analysis to connect what changed, where it propagated, and why it created user impact.
AIOps Must Fit the Incident Workflow
During an outage, teams don’t need yet another console. They need useful evidence in the systems where response already happens. That may mean ServiceNow, Slack, PagerDuty, runbooks, incident channels, or internal reliability portals.
This workflow reality is easy to underestimate. Even a strong technical insight loses value if responders have to leave the incident flow to find it. A practical AIOps platform should enrich existing workflows with root-cause context, incident prediction, duplicate suppression, and recommended next steps tied to operational knowledge.
That’s the practical direction behind InsightFinder’s approach to modern AIOps. The platform is designed to help teams move from reactive event correlation toward predictive reliability workflows that use anomaly detection, causal analysis, and workflow-native recommendations. For teams managing complex enterprise systems, that shift can change what responders do first.
How to Judge AIOps Platforms
The next generation of AIOps shouldn’t be judged by how many alerts it groups. It should be judged by whether it improves incident outcomes. Does it surface weak signals before customer impact? Does it distinguish causes from symptoms? Does it reduce the time needed to build a credible hypothesis? Does it fit the workflow responders already use?
Those questions matter to SREs and on-call responders, but they also matter to CTOs and engineering leaders. Alert volume isn’t a business problem. But prolonged degradation, customer-facing incidents, escalation fatigue, and slow diagnosis caused by the pain of sifting through correlations looking for answers is a business problem that needs solving.
Correlation can make operations look more organized. Causality makes operations more effective.
Move Beyond Correlation-Heavy AIOps
AIOps still has a strong future, but only if it moves past the limits of static rules and after-the-fact correlation. Modern systems need earlier detection, richer telemetry, causal reasoning, and workflows that help teams act before small anomalies become major incidents.
Check out our webinar to explore that shift in more detail. See why correlation alone isn’t enough, or request a demo to evaluate how InsightFinder can bring a more modern, predictive approach to AIOps in your own environment.
