InsightFinder AI & Observability Blog
Filter posts by category

Composite AI for IT Observability: Why Generative AI Alone Is Not Enough
Composite AI refers to the use of multiple AI techniques, such as unsupervised learning,…
Read more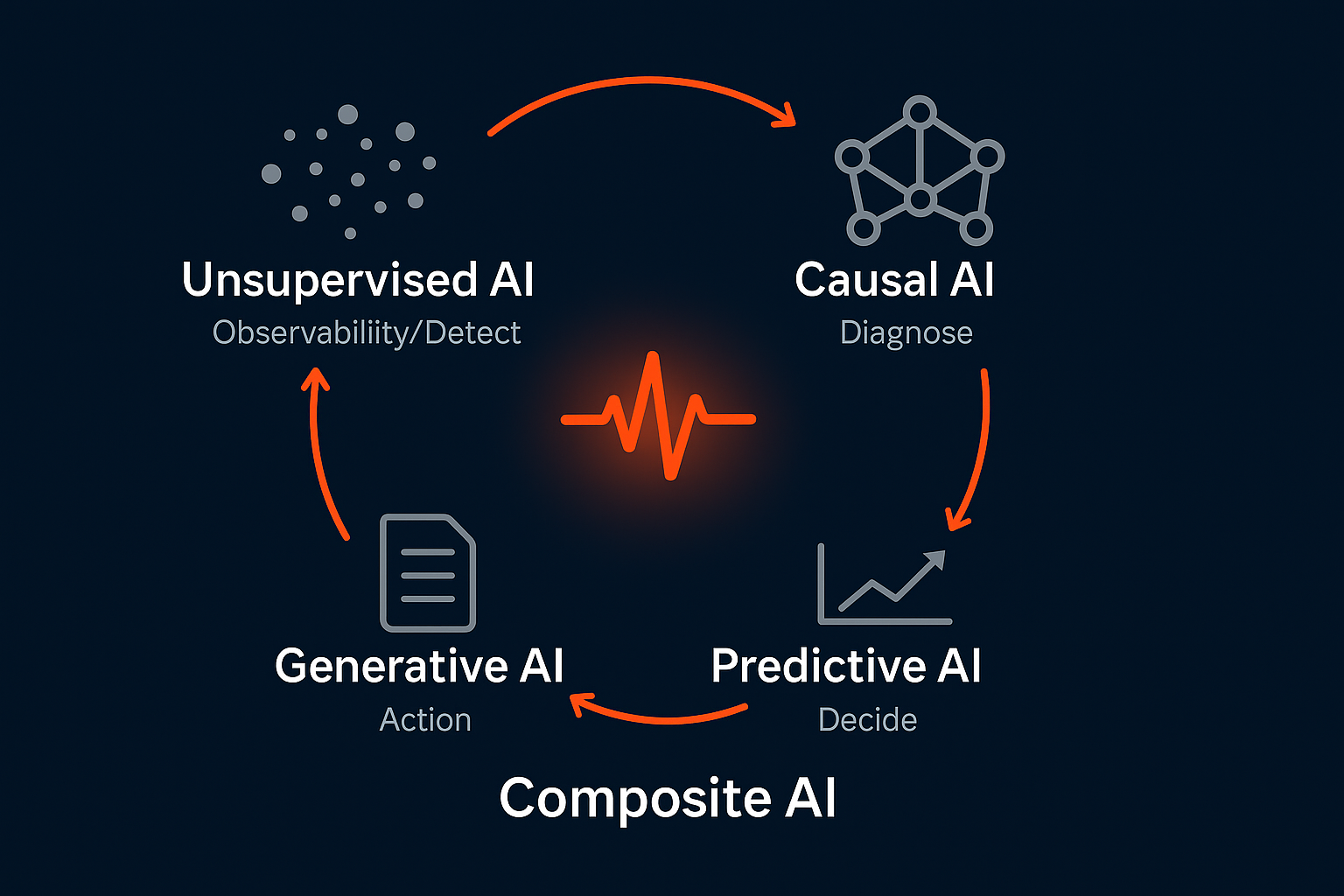
What Is Composite AI? A Practical Guide to Reliable and Trustworthy AI Systems
InsightFinder’s Composite AI blends unsupervised ML, predictive drift modeling, causal dependency mapping, and GenAI summaries into one cohesive reliability engine.
Read more
Debugging Faster with Distributed Traces in InsightFinder AI Observability Platform
With AI applications, any single request can fan out into session state checks, prompt…
Read more
Infrastructure Signals Every AI Team Should Monitor to Prevent Outages
AI outages rarely begin as dramatic failures. They tend to emerge quietly, shaped by…
Read more
Hallucination Root Cause Analysis: How to Diagnose and Prevent LLM Failure Modes
The prevalent view treats LLM hallucinations as unpredictable, sudden failures—a reliable system unexpectedly generating…
Read more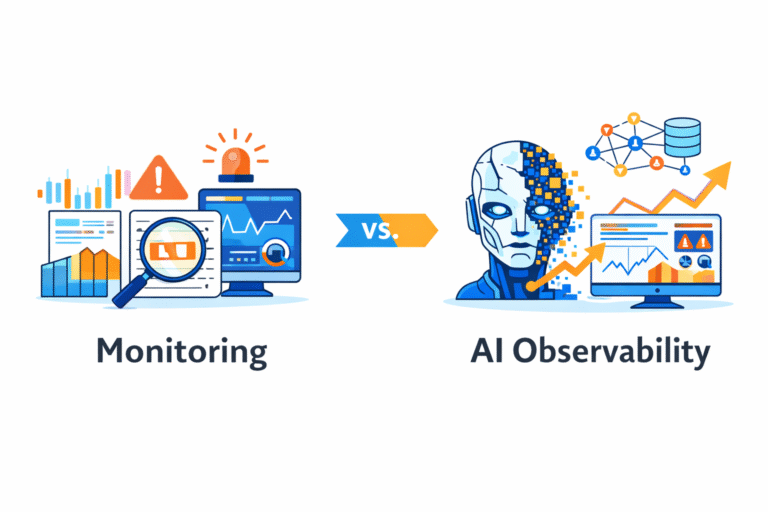
AI Observability vs Monitoring: Key Differences and When Each Approach Matters
Many engineering teams still use the terms “monitoring” and “observability” interchangeably. At first glance,…
Read more
Generative AI Observability: Ensuring Accuracy and Reducing Hallucinations
Generative AI has reached the point where powerful models are widely available, yet reliability…
Read more
Why Do LLMs Hallucinate? How Observability Tools Can Help Detect It
Large language models have moved quickly from experimentation to production. They now sit behind…
Read more
The Hidden Cost of LLM Drift: How to Detect Subtle Shifts Before Quality Drops
Large language model drift rarely announces itself. In most production systems, the model continues…
Read more
What Is the AI Reliability Problem and Why Do High-Quality Models Decay in Production?
AI systems fail more often than engineering teams expect, and they often fail without…
Read more
Understanding Model Drift: Types, Causes, and How to Detect it Before Accuracy Drops
AI models rarely maintain peak accuracy indefinitely. Whether deploying classic machine-learning models or state-of-the-art…
Read more
Why Predictive Analytics Is Critical for Cloud Infrastructure Monitoring
Modern cloud infrastructure is a complex, rapidly changing ecosystem utilizing microservices, containers, distributed storage,…
Read more
Proactive Reliability: How Predictive Observability Reduces Outages Through Early Detection
Most organizations still learn about system issues only after performance declines or customers begin…
Read more
Key Metrics for Measuring AI Observability Performance
As AI-driven systems, LLM workloads, and distributed architectures expand in scale and complexity, the…
Read more
5 Common Observability Pitfalls and How Predictive Analytics Solves Them
Many engineering teams have invested heavily in observability platforms, yet the same operational problems…
Read moreSee how InsightFinder helps your team deliver reliable services across every layer of the stack
Take InsightFinder AI for a no-obligation test drive. We’ll provide you with a detailed report on your outages to uncover what could have been prevented.
