
AI systems are forcing engineering leaders to confront an uncomfortable reality: the observability practices that work for microservices often fail when the “service” making decisions is probabilistic. In a recent interview on Triangle Tweener Talks, Dr. Helen Gu, CEO/Founder of InsightFinder and NC State Professor, framed this as a “last mile” problem. Teams can adopt powerful models quickly, but struggle to make them dependable in enterprise production environments where correctness, repeatability, and fast incident response matter.
This post unpacks why traditional observability reaches its limits in AI systems, what replaces it, and how teams can regain reliability without pretending dashboards alone can explain model behavior.
The Observability Model We All Internalized
Classic observability assumes a few stable truths. Systems emit telemetry that maps cleanly to components. Incidents have a relatively consistent “shape” in metrics, logs, and traces. When latency spikes, errors climb, or saturation appears, engineers can usually follow traces to a root cause and then verify the fix with the same signals.
This model works because most software is deterministic. Given the same input, it produces the same output. When it fails, the failure tends to be legible: a timeout, an exception, a bad deployment, a capacity ceiling.
AI changes the contract. The model becomes part of the control plane for decisions, not just a function you call. And with LLM applications, the “input” is not only data. It includes prompts, tool calls, retrieved context, prior conversation state, and chain-of-thought-like intermediate reasoning that teams often cannot or should not store.
Why AI Incidents Don’t Behave Like Microservice Incidents
Helen’s career has focused on reliability in distributed systems, and her description of why prediction matters is telling: humans react well but predict poorly, and distributed failures become harder to recover once they cascade. Her long arc in anomaly detection and SRE collaboration reflects a simple lesson: the cheapest incident is the one you catch before it becomes visible to users.
AI systems make that harder because the failures are rarely single-point. A customer-facing AI assistant may “work” at the infrastructure layer while failing at the outcome layer. You can have green dashboards and still ship incorrect answers, unsafe actions, or silently degraded quality.
That is the first limit of traditional observability in AI: it measures system health, not decision integrity.
Consider a familiar situation: latency and error rates look fine, but ticket volume climbs because the assistant gives confident, wrong guidance after a retrieval index change. Traditional observability can confirm that the service stayed up. It cannot explain why outputs drifted, which sources influenced the response, or whether the model started leaning on irrelevant context.
In other words, AI failures often live above the boundary where classic telemetry ends.
Metrics, Logs, and Traces Cannot Fully Explain Probabilistic Outputs
Teams try to adapt by logging prompts, responses, and token usage, then building dashboards for “LLM observability.” That helps, but it still assumes the system is introspectable with the same primitives.
The second limit appears when the core incident is semantic. A metric can tell you token count grew 30 percent. It cannot tell you the model began over-trusting a stale policy document. A trace can show the retrieval tool ran. It cannot tell you the retrieved passages were subtly off-topic, or that the model latched onto one misleading sentence.
This becomes even more acute with agentic systems. Once an AI agent can call tools, create tickets, change configurations, or trigger workflows, the “incident” might be a sequence of actions that are locally rational but globally wrong. Traditional distributed tracing captures the call graph. It does not capture whether the reasoning that chose those calls was sound.
The Hidden Gap: Machine Telemetry Versus Natural Language
One of Helen’s clearest points in the interview is that not all data is the same. Large language models excel at processing and generating human language, but “machine data” is different: high-dimensional, noisy, and full of numeric patterns that do not behave like prose. She argues that asking an LLM to do prediction or anomaly detection on numerical telemetry typically produces poor results.
This matters because many teams implicitly assume an LLM can become the universal observability layer. They wire up a chat interface to logs and expect it to replace analysis.
In practice, AI reliability needs multiple kinds of intelligence working together. You need models and methods that understand machine telemetry deeply enough to detect weak signals early. Then you need language models to translate those signals into narratives humans can act on quickly. Helen describes this as “composite AI,” where different techniques handle different data types and tasks.
Traditional observability stacks were not designed for this division of labor. They treat machine telemetry as the end product. AI systems need telemetry intelligence first, then human-friendly explanations.
The “Last Mile” Problem in Enterprise AI Reliability
Helen’s “last mile” framing fits what many teams experience. Getting a model to demo well is easy. Making it consistently correct in messy production conditions is not. She points to the last 10 percent of enterprise readiness: domain expertise, the right tools, and often fine-tuning or adaptation steps that many organizations cannot execute reliably.
Traditional observability struggles here because it was built to validate deployments and uptime, not truthfulness, correctness, or business-specific constraints. When the system is probabilistic, the question is no longer “did it error?” Now, it’s “did it behave within acceptable bounds?”
That last mile is where AI incidents turn into credibility incidents. A model that answers confidently when it is wrong becomes dangerous, even if infrastructure metrics are perfect. Helen warns that LLMs often do not say “I don’t know,” and that over-trust can become risky, especially in high-stakes contexts.
This creates a reliability requirement that classic observability never had to satisfy: you must continuously validate decision quality, not just system performance.
Dashboards Don’t Scale When the Interface Becomes an Agent
A quiet shift is happening in how engineers consume observability. Dashboards became popular because they compressed complex systems into visual primitives. But Helen notes that as natural language agents become interfaces, the bottleneck changes. It becomes less about visualizing every chart and more about asking the right question and receiving the right evidence fast.
This is the third limit of traditional observability: it assumes the human will manually traverse data. AI Operations does not scale with “more dashboards.” It scales with automation that mirrors how SREs actually debug.
She describes a workflow that looks like an experienced responder: check whether the database is healthy, verify upstream dependencies, inspect anomaly timelines, correlate signals, narrow scope, then form a causal hypothesis. The process repeats across incidents because the shape of debugging is consistent even when the underlying failure differs.
Traditional observability platforms can provide the raw evidence for this workflow, but they do not execute it. In AI-heavy environments, executing it quickly matters more because the surface area is larger: models, prompts, tools, retrieval, orchestration, and the underlying infrastructure.
What AI Systems Need Instead of “More Observability”
When traditional observability hits its limits, the replacement is not abandoning telemetry. It is adding layers that classic stacks were never built to deliver.
AI systems need earlier detection of subtle changes because “failure” often starts as a weak signal, not an error spike. They need correlation across heterogeneous telemetry because LLM applications blend machine signals with semantic behavior. They need causal reasoning support because the path from symptom to root cause is less direct. And they need automation that shrinks the time between “something feels off” and “here is what changed, why it matters, and what to do next.”
Helen describes approaches like predicting incidents hours ahead in some production settings, and she emphasizes validating results through replay of historical incidents, so teams can see whether the system would have detected issues earlier under realistic conditions.
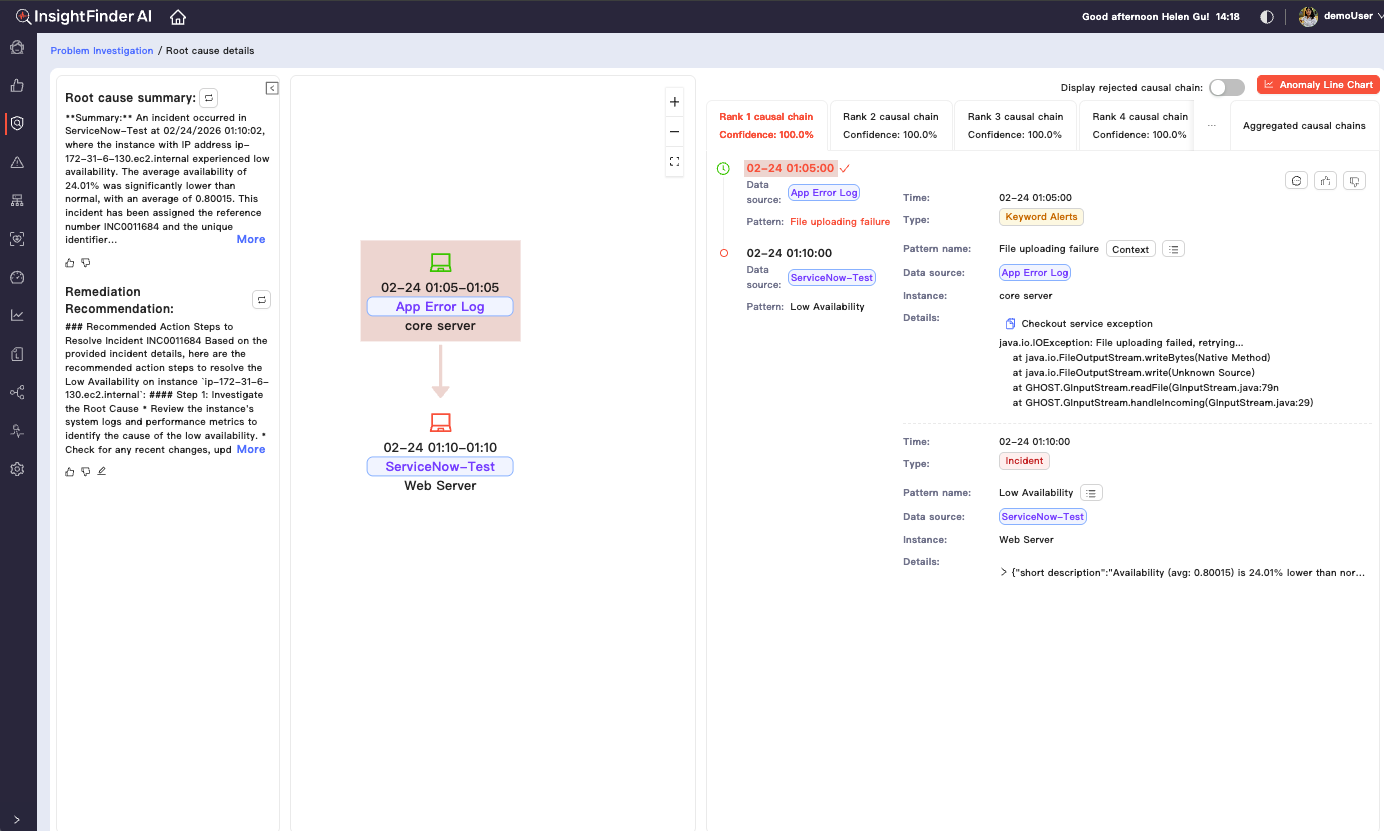
The important takeaway is not any single technique. It is the posture: reliability comes from closing the loop between detection, diagnosis, and action, not from collecting more data.
A Practical Way to Think About the Next Observability Stack for AI
Engineering leaders need a better mental model in order to create unified solutions for their modern stacks.
Keep the classic telemetry pipeline, but treat it as raw material, not the answer. Add analytics that can actually operate on machine telemetry at scale, including anomaly detection and predictive signals. Then use LLMs where they are strongest: turning complex technical findings into clear, human-readable incident narratives, and acting as an interface that can retrieve evidence on demand.
This is the composite approach Helen describes: unsupervised AI to surface anomalies, predictive AI to forecast incidents before they impact users, causal AI to pinpoint likely drivers and blast radius, and generative AI to turn machine signals into fast, human-readable investigation workflows.
It also aligns with how modern SRE teams work under pressure. They don’t need yet another dashboard. They need fewer dead ends, faster narrowing, and better confidence in what to do next.
Traditional Observability Isn’t “Wrong,” It’s Incomplete for AI
Traditional observability remains necessary. It just stops being sufficient when systems make probabilistic decisions, when failures are semantic, and when agentic workflows turn small mistakes into real-world actions.
The limit is not data collection. The limit is interpretation and automation. AI systems demand observability that can predict, correlate, explain, and assist remediation in ways dashboards alone cannot.
If this perspective resonates, it is worth listening to the full podcast episode featuring Dr. Helen Gu, where she discusses the “last mile” of enterprise AI, why machine telemetry differs from language, and how AI-driven workflows can mirror how SREs investigate incidents in practice.
To see how these ideas translate into production workflows, request a demo of InsightFinder and evaluate how predictive detection, correlation, and AI-assisted investigation can fit into your existing observability stack.
