
Production reliability is hitting a breaking point. As systems become more distributed and deployments accelerate in an AI era, your operational surface area quickly expands. Strong observability detects issues, but the toughest part of on-call remains after detection occurs: correlating changes, prioritizing what matters, and safely acting before the problem escalates.
Today, we’re announcing the ARI (Autonomous Reliability Insights) Agent, designed to sit inside reliability workflows and turn operational signals into actions. ARI isn’t meant to replace engineers. Instead, it reduces the mechanical load that makes incident response brittle at scale by keeping context connected across incidents, anomalies, predictions, and change events.
Why “seeing it” still leaves teams stuck
Observability made modern systems survivable. Metrics, logs, traces, events, and alerts create the shared ground truth teams need when systems are so complex that no one person can keep the full dependency graph in their head. It’s vital and necessary, but we still need more.
The reality for SRE, DevOps, and platform teams is that observability alone can’t close the loop. An alert triggers, dashboards light up, and now someone has to do the expensive work: gather context, correlate signals, figure out what changed, narrow down suspects, and write an update other humans can trust. Those steps repeat incident after incident, even when the triggering failure modes differ each time.
Meanwhile, most organizations are layering AI systems on top of their already complex platforms. That piles on new operational variables that can shift quickly: model behavior, retrieval pipelines, tool calls, prompt changes, policy updates, and cost and latency patterns that move with traffic. Observability remains foundational, but the gap between “I can see it” and “I can fix it safely” keeps widening.
Operational AI agents are a response to that widening gap. Some agents are implemented as simple chatbots sitting in your incident channel. But the real value comes from agents that can carry real operational context across workflows so engineers spend more time on judgment instead of burning it on mechanics.
Meet ARI: an operational AI agent grounded in platform context
ARI is an operational AI agent that enables natural-language interaction with InsightFinder’s reliability platform. It provides real-time access to operational insights such as causal chains across incidents, predictive alerts, recommended and executed actions, anomalies in metrics and logs, and problematic change events.
There’s an emphasis on that “operational” part. Reliability questions are almost never generic. “What should we do next?” depends greatly on operational environments, business domain, deploy cadence, recent changes, dependency chains, and risk tolerance. ARI is designed to be useful in real-time by retrieving and presenting validated and precise evidence from the systems you already monitor, then helping you drill down with all the contextual information you need. ARI is designed as your operational partner, loaded with the all the right context.
That’s possible because of where ARI lives. ARI is integrated into your incident response workflows so the interaction starts with the same notifications reliability teams already use. For existing InsightFinder customers, ARI is available within the IT Reliability portion of our platform. Further, if you want to fine tune ARI’s default behaviors, the AI Reliability portion of our platform is built-in—making it fast and easy to tailor ARI to your needs.
Let’s dive into how ARI works.
Instant Context Summary for What is Happening Today: a “shift handoff” that starts with evidence
ARI begins by doing something reliability teams often want but don’t have time to do in practice: it builds an operational context narrative—as soon as you login.

ARI displays an operational summary when you login to the platform.
When you login, ARI automatically generates an operational summary for the past 24 hours that reports on all systems you own or have access to. That summary includes an aggregated overview of incident, metric anomaly, log anomaly, and change event counts. Plus it includes a table that highlights your top unhealthy systems prioritized by incident counts.
But this summary isn’t just a scoreboard. ARI adds natural-language explanations that bring you up to speed on recent incidents, real-time prediction results, and preventive actions taken to mitigate or avoid predicted incidents. In practice, this acts like an always-on shift handoff: what happened, what’s trending riskier, and what actions have already been taken so you won’t repeat work.
For executives and stakeholders, that daily summary is also a practical bridge between top-level questions like “are we stable?” and engineering-level “what exactly is unstable?” investigation. It compresses any ongoing operational noise into an evidence-backed snapshot that can be read quickly, then expanded as needed by asking ARI follow up questions.
On-demand context retrieval: conversational drill-down with continuity
During an incident, figuring out the failure mode isn’t typically hard part (especially if you have great observability). The hard part is the continuity of context: what changed, what else looks abnormal, what’s correlated versus causal, and where the investigation should focus next.
ARI’s on-demand context retrieval is designed for that drill-down workflow. In a single session, users can ask continuous, follow-up questions to gain a deeper understanding of a system’s status. ARI returns context as markdown strings, tables, and line charts, which makes it easier to move from a narrative answer to something you can validate.

Conversations with ARI can start with high-level questions.
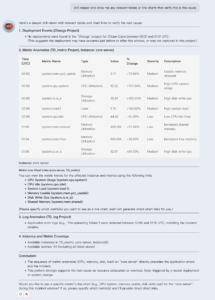
Then, you can do things like ask ARI to show you proof: what led to this diagnosis?
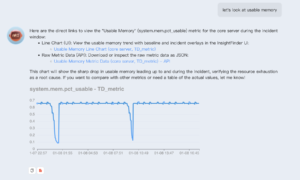
Keep going and let ARI surface details you need quickly.
This is where ARI’s grounding in platform signals and operational context really shines. Instead of engineers jumping between tools to reconstruct an incident timeline, ARI can help retrieve the relevant incident context, then continue the conversation as the scope narrows. Let ARI do the mechanical grunt work that’s often where teams burn most of their response time.
Comparison reporting: quantifying system improvement
Reliability work lives across two time horizons: the acute horizon of incident response, and the chronic horizon of system health (over weeks and months). Many teams struggle to connect those horizons because it takes significant time to create credible before-and-after views.
ARI includes a dedicated Comparison Report feature that provides a side-by-side view for a system across different time periods to analyze health and performance changes. That comparative perspective helps teams understand system evolution and measure long-term stability.
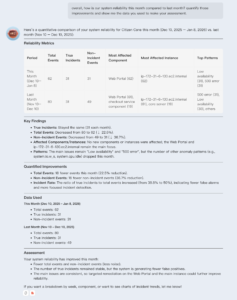
Ask ARI to create comparisons that leverage any of the data you’ve captured in the InsightFinder platform.
For engineering leaders, this can mean massive time savings or even the ability to something they might not always have time to do. Investments in prioritizing reliability work needs proof. It’s not enough to say a mitigation worked. Teams need to show whether incident frequency dropped, anomalies quieted down, and new changes correlate with either performance improvements or regressions. A comparative view anchored in the same operational evidence used during incidents helps make that case without reinventing the reporting process every quarter. ARI can manage that for you quickly and easily.
Where ARI fits in the reliability workflow
ARI is designed to live inside the reliability workflow, whereas most other agents simply sit beside it. That placement reduces friction between tools and decisions by helping teams diagnose issues using real operational context, then accelerating the path to safe next steps.
In practice, that means ARI is most valuable in the moments when human attention is most expensive. We’ve already seen one of those moments: early triage. When an engineer gets paged, and needs a fast answer, as soon as they open the platform, ARI’s daily summary appears which starts with current active issues.
But another key moment is during incident escalation. Incident commanders need a clean narrative for stakeholders, or when reaching out to loop in additional help. Responders need a clean up-to-date trail of evidence that everyone can follow. Collecting that information manually often burns critical time and effort, further extending incidents. ARI’s ability to return structured tables and charts alongside natural-language explanations is meant to support validation, not just conversation.
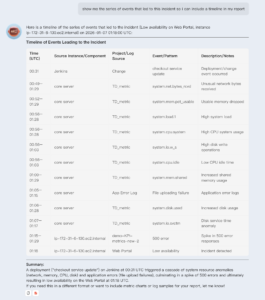
ARI can immediately deliver accurate timelines, ensuring your responders focus attention on what matters most.
Another key drain of human focus happens in preparation for post-incident learning. Much of the preparation work is rote and time consuming. Teams want to know what happened, which fix worked, and what the impacts were. Typically, that means spending hours gathering data and collating it for human consumption. ARI can gather findings and recap events so that your teams focus on learning rather than doing the grunt work of manually connecting the dots.

Ask ARI to summarize key events, incident impacts, and lessons learned.
In practice, ARI gives your teams an ability to massively accelerate reliability work.
Regardless of the specific causes or mechanics, most incident response is exactly the same sequence of work: engineers pull signals from multiple places, correlate what changed with what broke, narrow down suspects, summarize for other humans, propose next actions, and then carry out safe mitigations. Afterward, they document what happened and codify fixes so the organization learns and systems improve.
None of that is optional. But much of that work is mechanical. And too much of it consumes the most expensive resource we have: focused human attention under pressure.
ARI shrinks lengthy incident cycles by making operational context precise, structured, and instant across the reliability workflow.
ARI uses production feedback for continuous improvement
Last, but certainly not least, ARI is built for continuous improvement that you can accelerate.
Operational agents only get better if they learn from real environments. Production is where edge cases appear, where true system behavior shows under load, and where the team’s decisions define what “good” means in that architecture.
As ARI operates in your environment, learning compounds via the composite AI techniques embedded within the InsightFinder platform. ARI will adapt to your data sets, learn with each incident, and start to proactively predict and prevent future incidents.
However, each company is different and your business context is unique. If ARI isn’t understanding your business context quickly enough, you can use the continuous improvement workflows in the AI observability portion of our platform to reinforce learning from real-world signals and user feedback. You can fine tune ARI’s underlying model using built-in tools that are included out-of-the-box.
It’s very important to frame this accurately: learning systems are probabilistic, and behavior is expected rather than guaranteed. What matters operationally is whether teams can create tight loops between production evidence, human feedback, and improved future responses. ARI is built to support that direction by keeping operational context accessible and by making it easier to capture what humans learned, then reuse it in the next investigation.
ARI is available today
If you’re already an InsightFinder customer, you can try ARI today by opening the IT Observability portion of our platform. Open it up and start using ARI in the workflow where you already operate, with the signals and context that already exist in your environment.
If you’re new to InsightFinder, contact us for a demo so we can show you what ARI would look like in your organization, with your specific services, and understanding your specific business context.
