Welcome to InsightFinder AI Observability Docs!
Categories
LLM Gateway
Architecture
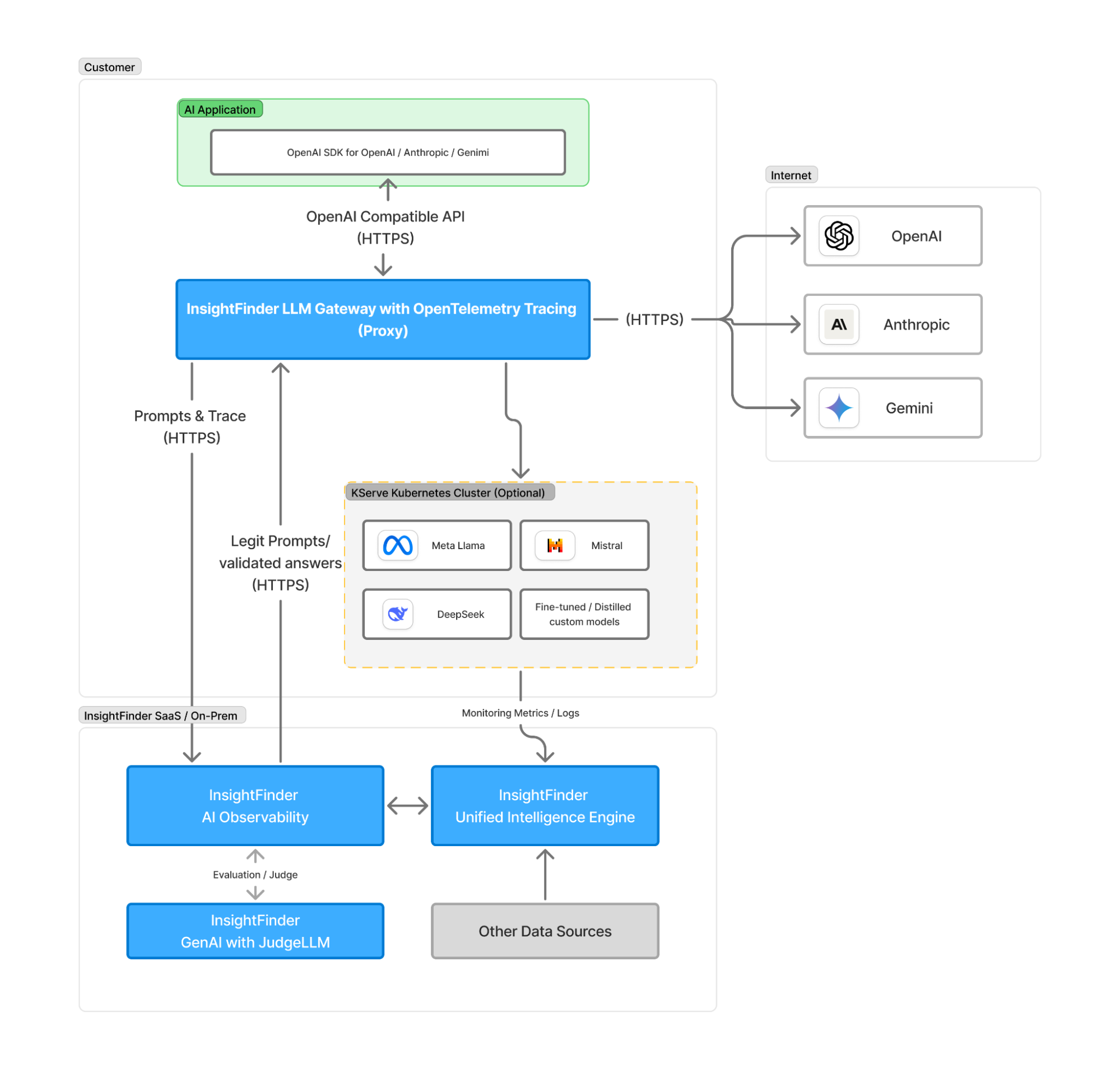
1. Client AI Application
- Built using OpenAI SDK with compatibility for OpenAI, Anthropic, and Gemini models
- Provides a standardized interface for customers to interact with various LLM providers
- Communicates via OpenAI Compatible API over HTTPS
2. InsightFinder LLM Gateway with OpenTelemetry Tracing
- Accept OpenAI-compatible API calls.
- Central component that load-balances requests to appropriate LLM providers.
- Implements OpenTelemetry for distributed tracing and observability
- Protect LLM models from outputting sensitive information by introspecting malicious prompts.
- Safeguard the LLM responses by evaluating them using the InsightFinder AI platform.
- Acts as a unified API endpoint for multiple AI services
- Handles authentication, rate limiting and other security features.
3. External LLM Providers
The gateway connects to three major AI service providers:
- OpenAI: GPT models and related services
- Anthropic: Claude models (including the current Claude Sonnet 4)
- Gemini: Google’s LLM offerings
All connections to external providers use HTTPS for secure communication.
4. Kserve Model Hosting Infrastructure (Optional)
- Optional component for hosting custom or fine-tuned models
- Includes support for:
- Meta Llama: Open-source LLM deployment
- Mistral: Efficient language models
- DeepSeek: Specialized AI models
- Fine-tuned/Distilled Custom Models: Organization-specific trained models
5. InsightFinder Platform Components
InsightFinder AI Observability
- Collects and analyzes prompts and trace data from the gateway
- Provides evaluation and judgment capabilities through integration with GenAI
- Monitors LLM performance, usage patterns, and quality metrics
- Receives legitimate prompts and validated answers via HTTPS
InsightFinder Unified Intelligence Engine
- Central intelligence component that processes monitoring metrics and logs
- Integrates with other data sources beyond LLM interactions
- Provides comprehensive analytics and insights
InsightFinder GenAI with JudgeLLM
- Specialized component for evaluating LLM responses
- Provides quality assessment and validation of AI-generated content
- Feeds evaluation results back to the AI Observability component
Highlights
- The dedicated gateway service is open-source and available to everyone.
- It takes very little code changes in the customer AI application if it’s already using OpenAI SDK or compatible API.
- The InsightFinder platform will serve as a guardian without touching the core business logic.
- The prompt / response requests are reaching out to the LLM model providers directly.
- The system is highly scalable both horizontally and vertically.
Data Flow
Stage 1: Request Initiation
When a user initiates a chat request through the OpenAI SDK in the application, the system performs initial validation and formatting. The request header includes:
- Username: The username of InsightFinder AI platform.
- API key: The username of InsightFinder AI platform.
- Prompt: User’s input text
Stage 2: Gateway Processing
The gateway orchestrates multiple parallel processes upon receiving a request:
2a. Malicious Prompt Detection
The system checks incoming prompts for potentially harmful content through validation rules and pattern matching. If malicious content is detected, the request triggers an alert and appropriate response handling.
2b. Model Session Retrieval
The gateway retrieves the detailed model access information from the configuration in the InsightFinder AI platform.
2c. Stream chat response with LLM Models
The gateway will connect with the corresponding model provider and stream the chat response.
2d. Chat Status Reporting
The gateway reports the following statistics to the InsightFinder AI platform:
- Token usage.
- Connection error code if any.
- Connection error message if any.
2e. Chat content evaluation
The gateway will query the InsightFinder AI platform to evaluate the chat responses to know if the AI models is answering accurately in the following areas:
- Hallucination & Irrelevance
- Safety, Guardrails & Toxicity
- Bias
- Refuse to Answer
- etc.
Stage 3: Response Delivery
The Gateway will then return the chat response to the original application if the response passed the malicious prompt checking and all evaluations.
From the Blog



See how InsightFinder helps your team deliver reliable services across every layer of the stack
Take InsightFinder AI for a no-obligation test drive. We’ll provide you with a detailed report on your outages to uncover what could have been prevented.
