
LLM adoption has moved faster than the infrastructure supporting it. Teams are rolling out applications built on OpenAI, Anthropic, and an array of open-source models at a pace that rivals the early days of cloud. But that speed has come with a cost. Most organizations today are managing a patchwork of APIs, authentication schemes, and monitoring strategies—one for each model provider. The result is fragility, blind spots in production, and unnecessary operational risk.
That’s why we built the InsightFinder LLM Gateway. It is the first open-source, enterprise-grade gateway designed to sit between your applications and the large language models they call. It delivers a unified control point for security, reliability, and observability without requiring code rewrites or forcing teams into a single vendor ecosystem.
The Hidden Complexity of Multi-Model AI
If you talk to engineering teams building with generative AI today, a pattern emerges. They rarely use just one model. A customer-facing chatbot might default to OpenAI for its fast responses but fall back on Anthropic Claude when safety is critical. A research team may run a fine-tuned Meta Llama model locally to keep data private and costs manageable. Product managers often ask for side-by-side testing of models like Mistral or DeepSeek to compare quality and latency tradeoffs.
Each of these choices adds flexibility for the business but creates a headache for engineering. Different APIs mean different SDKs, authentication tokens, rate limits, and monitoring strategies. Switching from one model to another can require rewriting sections of code. Running multiple models in production often leads to duplicate logging, fractured monitoring, and uncertainty about which requests are driving costs.
The challenge becomes even more apparent in production incidents. Imagine a customer support AI suddenly refusing to answer common queries. Was the issue with OpenAI’s API? Did Anthropic throttle requests? Or did the application silently fail over to a local model with incomplete guardrails? Without centralized visibility and routing, teams are left guessing while downtime ticks by.
Why Existing Approaches Fall Short
Some organizations attempt to solve this by writing abstraction layers on top of each provider. While that might reduce surface-level complexity, these homegrown wrappers often lack enterprise-grade capabilities. They rarely include comprehensive logging, security controls, or real-time failover logic. More importantly, maintaining them requires ongoing engineering effort, which quickly becomes unsustainable as providers update their APIs or release new models.
Others try to standardize on a single vendor, hoping to simplify operations. But this locks them into one ecosystem, often at the expense of cost, safety, or performance. A vendor that is ideal today may not remain competitive tomorrow. The pace of innovation in the LLM space means the “best” model is a moving target. Without the ability to switch providers easily, organizations risk being stuck with yesterday’s technology at tomorrow’s prices.
The Gateway as an Infrastructure Layer
This is where the InsightFinder LLM Gateway changes the equation. Rather than forcing teams to manage every provider individually, the gateway acts as a unified API endpoint and intelligent load balancer. Built to accept OpenAI-compatible API calls, it plugs directly into applications already using the OpenAI SDK with minimal changes. From there, requests can be routed to OpenAI, Anthropic Claude, Google Gemini, or self-hosted open-source models like Llama, Mistral, and DeepSeek.
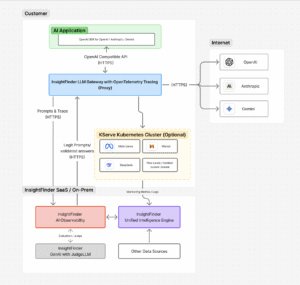
InsightFinder’s LLM Gateway sits between your applications and underlying LLMs. It also integrates with the rest of the InsightFinder AI platform including the AI observability platform and Unified Intelligence Engine.
This design shifts complexity out of the application and into a dedicated infrastructure layer, where it belongs. Developers continue to code against a single interface, while the gateway handles authentication, rate limiting, failover, and load balancing across providers. For DevOps and platform teams, it becomes the control point for enforcing policies, monitoring usage, and scaling capacity.
Think of it as the equivalent of an API gateway in microservices architecture. Just as API gateways standardized routing and security for distributed systems, the LLM Gateway provides a foundation for enterprise-scale AI adoption.
Observability That Matches Production Demands
Visibility is often the first thing to break down when organizations scale LLM usage. Token consumption can spike without warning, leading to runaway costs. Latency issues might creep in when models are overloaded, but the root cause is hard to pinpoint without distributed tracing. Failures may appear sporadic and random without structured error logging.
The LLM Gateway addresses these gaps with built-in OpenTelemetry instrumentation. Every request through the gateway generates traces, metrics, and logs that can be analyzed in real time. Token counts are tracked at both input and output, giving teams fine-grained visibility into usage patterns. Latency and error codes are recorded for each provider, allowing faster diagnosis of performance regressions.
For example, if latency suddenly doubles for a customer-facing chatbot, the gateway’s traces can reveal whether the slowdown is specific to one model provider, a networking bottleneck, or an upstream failure. If token usage unexpectedly spikes, engineers can see which users or services are driving the increase and take corrective action before bills escalate.
These observability features put AI interactions on equal footing with microservices. Instead of operating in the dark, teams gain actionable insights for capacity planning, debugging, and optimization.
Security and Trust at the Application Boundary
Generative AI introduces new security concerns that traditional infrastructure was never designed to handle. Malicious prompts can be crafted to extract sensitive information, inject toxic content, or manipulate responses in subtle ways. At the same time, model outputs themselves may introduce bias, hallucinations, or unsafe recommendations.
The LLM Gateway addresses these challenges by screening and safeguarding interactions on both sides of the request/response loop. Incoming prompts are validated for harmful or malicious content before they reach a model. Outgoing responses are evaluated by InsightFinder’s JudgeLLM, which checks for issues like hallucination, toxicity, bias, or refusal to answer.
This dual-layer protection is particularly important in regulated industries. A financial services chatbot that inadvertently suggests risky investment strategies or a healthcare assistant that provides misleading guidance could create legal and reputational exposure. By inserting evaluation and auditing at the gateway, organizations gain an additional safety net without having to modify each application or model.
The result is not just better security but greater trust. Teams can document and audit every interaction, making it easier to demonstrate compliance with industry standards and internal policies.
Reliability Without Vendor Lock-In
In production, reliability is just as critical as security. Outages are costly, and failover mechanisms are essential when relying on third-party providers. The LLM Gateway builds these capabilities into its architecture. Requests are intelligently load-balanced across providers, and automatic failover can route traffic to backup models if the primary fails.
Consider an AI-powered customer service assistant that depends on OpenAI as its primary provider. If OpenAI experiences downtime, the gateway can seamlessly redirect traffic to Anthropic Claude or a self-hosted Llama model, ensuring the application continues to function. Customers remain unaware of the disruption, and engineers can investigate the root cause without firefighting an outage.
This flexibility also future-proofs deployments. As new providers emerge or existing ones change pricing models, organizations can experiment, migrate, or diversify without rewriting applications. The gateway abstracts away the provider details, giving teams freedom to optimize for cost, latency, or quality as their needs evolve.
Real-World Scenarios
The value of the gateway becomes most clear in the day-to-day challenges faced by AI/ML engineers.
In one scenario, a product team building a conversational assistant for e-commerce needs fast responses during peak shopping hours. They configure the gateway to prioritize OpenAI for speed but automatically fail over to Anthropic Claude if OpenAI throttles requests. During Black Friday, this setup prevents downtime and keeps the shopping experience uninterrupted.
In another scenario, a healthcare startup fine-tunes a Llama model to run on local infrastructure for patient data privacy. They continue to use OpenAI and Anthropic for general queries but rely on the gateway to route sensitive requests exclusively to their local deployment. This allows them to comply with privacy regulations without building a separate API layer for each provider.
A third scenario involves an enterprise experimenting with new providers like Mistral and DeepSeek. Rather than writing new integrations for each, they connect them through the gateway. Developers continue coding against the same API, while platform engineers use the gateway’s dashboards to monitor performance differences and make informed choices about which models to scale.
These examples illustrate how the gateway turns what would normally be operational burdens—vendor juggling, reliability concerns, compliance risks—into manageable policies defined at the infrastructure level.
Why This Matters Now
The rapid adoption of LLMs has outpaced the maturity of supporting infrastructure. Without a layer like the InsightFinder LLM Gateway, organizations are left managing observability, security, and reliability piecemeal across each provider. This is not sustainable. Just as API gateways became indispensable in microservices architectures, an LLM gateway is becoming a critical enabler for enterprise-scale AI.
By consolidating model access, embedding safeguards, and instrumenting every interaction, the LLM Gateway allows teams to focus on building differentiated AI features rather than constantly re-engineering their infrastructure. It represents a shift from reactive, piecemeal operations to proactive, enterprise-grade management of AI in production.
Getting Started
The LLM Gateway is available today via the InsightFinder SDK. If your application already uses the OpenAI SDK, integrating the gateway requires only minimal changes. From there, you gain unified access to multiple providers, real-time observability through InsightFinder, and built-in safeguards for reliability and trust.
AI adoption doesn’t slow down for operational complexity—but your production systems shouldn’t pay the price. With InsightFinder’s LLM Gateway, you can ship faster while protecting your business.
Start exploring the LLM Gateway today. Request a free trial here or schedule time with our team.
