Choosing the right large language model (LLM) for your application has never been more critical—or more difficult. Public benchmarks showcase academic performance, but they never reflect the messy mix of jargon, tone, long-context reasoning, or compliance rules that your production systems demand. So, often, we spend weeks determining if a model fits our needs only to later find out it fails on hallucination, safety, bias, or cost in the real world.
In this post, we’ll show you how InsightFinder’s new LLM Labs provides a faster, safer, and more reliable way to test models against your actual use cases. It helps you move out of guesswork and into data-driven confidence.
It’s time to bring evaluation into the same category of observability rigor that we already demand from our production systems.
Why LLM Evaluation Feels Broken
If you’ve ever tried to select an LLM for a production workflow, you’ve probably run into the same problems. Benchmarks like MMLU or TruthfulQA are informative, but they’re built for academic comparability rather than domain specificity. A finance chatbot isn’t judged on high school math questions, and a healthcare assistant can’t afford to hallucinate a treatment plan because a dataset didn’t cover edge cases in medical terminology.
The gap between public benchmarks and actual workloads is compounded by the cost of evaluations themselves. Your primary concerns with subjective tasks are style, accuracy, and reasoning quality; all of which require expert judgment to codify. Few teams have both the domain expertise and the time to build detailed rubrics. Progress is slow. So many developers fall back on shallow tests. If the call returns a reasonable-looking answer, presume it’s good enough.
That shortcut often hides deeper risks like safety compromises, toxic outputs, or unintentional bias whose presence is only realized after the system is already live. What happens when security or legal reviewers flag unsafe behavior after deployment? Just ask anyone whose AI rollout initiatives have been stalled for months, or worse, rolled back.
And with new models arriving quickly—GPT-5 was just released, while Anthropic and Google continue to iterate and catch up—teams need a way to canary test updates without reinventing their evaluation processes every time.
Enter InsightFinder’s LLM Labs
LLM Labs gives AI and ML engineers a controlled, transparent environment where they can test, monitor, and compare LLMs against the scenarios that actually matter. Rather than relying on abstract benchmarks, LLM Labs lets you create dedicated evaluation sessions tailored to your specific use case.
Watch a demo to see how it works
Each session tracks not just the responses you see, but also their underlying quality, safety, and relevance. Real-time evaluation detects hallucinations, monitors for bias, and flags any leakage of sensitive data. Built-in guardrails provide safety monitoring without requiring you to design your own filters from scratch. The result is a workflow that combines the speed of experimentation with the rigor of quality assurance.
Making Comparisons That Matter
One of the more powerful features of LLM Labs is its Model Compare Dashboard. Here, you can run the same prompts across different models—or different versions of the same model—and see side-by-side results. Instead of guessing how Gemini 2.5 stacks up against GPT-4.1, you can evaluate them directly on your domain-specific prompts, with analytics that highlight differences in hallucination rates, safety performance, and bias detection.
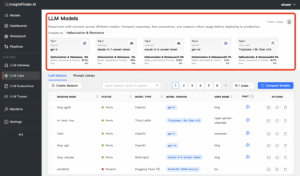
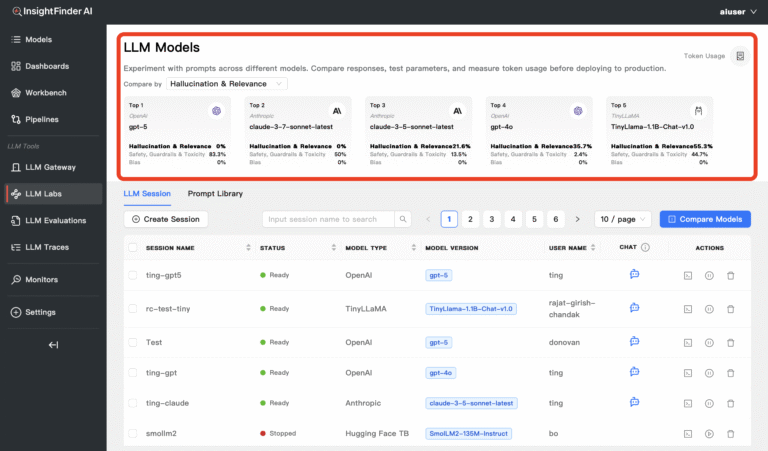
The model comparison dashboard quickly shows you how all of your models score against hallucinations & relevance, safety guardrails & toxicity, and bias.
LLM Labs also provides token usage tracking, making it easy to measure not only which model produces the most reliable output but also which one is more cost-efficient. That balance between quality and cost is critical for teams scaling production workloads, where even small differences in token efficiency can add up to substantial budget impacts.
From Single Conversations to Scalable Testing
LLM Labs supports both interactive sessions and batch prompt testing. You can chat with a model in real time to explore how it handles nuanced requests, or you can upload prompt packs to simulate real workloads at scale. A central Prompt Library allows you to store and reuse these prompt sets, so that every model is tested consistently against the same baselines.
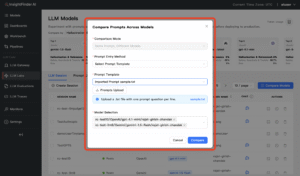
Upload prompt templates, run them against multiple models, and recall them for future use from your prompt library.
That consistency is key to avoiding the moving-target problem. With new model versions being released constantly, the ability to rerun tests against established prompt libraries gives you confidence that improvements (or regressions) are measured, not assumed.
Trust and Safety at the Core
LLM Labs goes beyond correctness to surface issues of trust and safety. Every response is automatically evaluated for signs of toxic language, prompt injection attempts, or data leakage. For teams in regulated industries, that alone can accelerate deployments and save you months of compliance reviews. Bias detection runs alongside safety analysis to flag stereotypes or unfair responses, helping ensure that your applications aren’t just accurate but also responsible.
The evaluation metrics are presented transparently, so you can see not just whether a model responded, but whether it responded safely, fairly, and relevantly. This is what separates LLM Labs from the “does it run” style of testing that dominates early-stage experimentation.
Faster Decisions, Lower Risk
In practice, LLM Labs shortens the path from idea to deployment. Instead of running ad hoc tests in notebooks or relying on vendor marketing claims, you can run structured evaluations in a controlled environment and make evidence-based decisions. The ability to canary test new versions means you can stay ahead of the rapid release cycle without putting production systems at risk. And by automating evaluation criteria that would otherwise require subject matter experts, LLM Labs reduces the bottleneck of manual labeling.
For AI & ML engineers, the benefit is speed. For decision makers, the benefit is confidence. For organizations, the benefit is avoiding costly surprises, such as discovering safety or compliance blockers late in the cycle or once they’re already live, and tarnishing your company’s reputation with real customers.
A New Standard for LLM Evaluation
As LLMs continue to evolve, complex evaluations simply can’t afford to remain an afterthought or a wishlist item. The industry needs tools that bring observability, safety, and repeatability to the model selection process. LLM Labs is InsightFinder’s answer to that need. It transforms evaluation from a one-off experiment into an ongoing discipline, integrated into the same workflows that teams already use for monitoring, testing, and observability.
We hope it will be your answer to that need, too.
Try LLM Labs Today
InsightFinder’s LLM Labs is now available for engineers and teams who want a smarter way to evaluate LLMs. Whether you’re comparing the latest GPT release against an Anthropic model, validating compliance for a healthcare assistant, or optimizing prompt efficiency for customer support automation, LLM Labs provides the framework you need to move forward with confidence.
Start your free trial today and see how LLM Labs can accelerate your path to safer, smarter, and more cost-effective AI systems.
