
InsightFinder can source logs from Elasticsearch and correlate it with other available data to generate anomalies and root causes, while also generating live predictions to prevent incidents and outages. Below is the documentation on how to install and configure the Elasticsearch integration with InsightFinder.
Prerequisites
Information and Items needed:
● Elasticsearch endpoint url
● Elasticsearch username and password
● Elasticsearch index to scrape data from
● Python 3.6.8 and Pip/pip3
● InsightFinder elasticsearch_collector
● InsightFinder endpoint and credentials
Project Creation
● On InsightFinder IT Observability, go to “Settings” -> “System Settings”. Click on “Add New Project”. (See Figure 1)
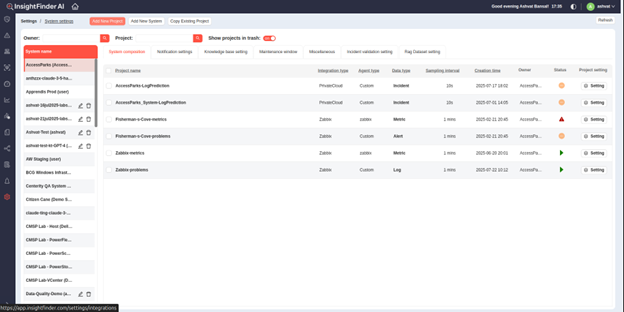
● In the Integration Filters, search for Elastic, and select the ‘Elastic Log’ Integration
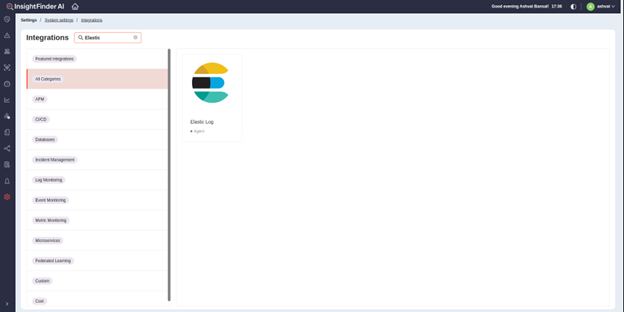
● After clicking on the Integration type, users will be redirected to the Creation Page. All the fields are pre-populated for Elastic Log Integration and can be left as default. Enter the desired project name and the System that the project should be part of.
● If choosing an existing system, the system can be selected from drop down. If you want to create a new system, just enter the new System name in the field, System will be created automatically.
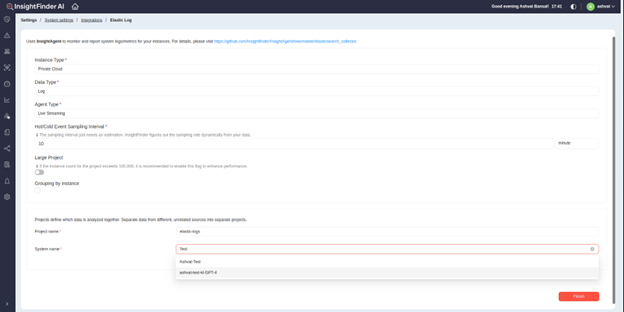
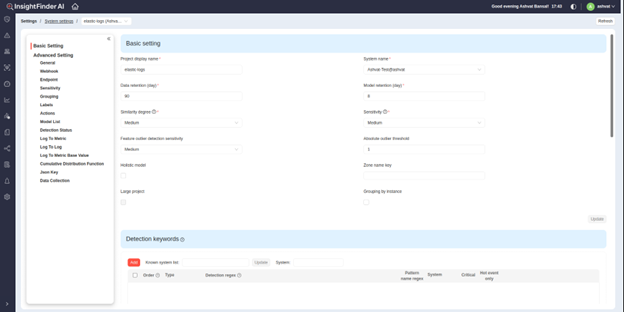
● Click ‘Finish’ to create the new project. Once a project is successfully created, you will be redirected to the settings page for the project, and should be good to use the project now.
Elasticsearch Collector
To send data to InsightFinder from Elasticsearch, you need to configure and set up the elasticsearch_collector provided by InsightFinder. The collector can be configured using the configuration file, which can be provided by InsightFinder UI.
Installation Steps:
- Download the elasticsearch_collector.tar.gz package (Would generally be provided by DevOps Engineers)
- Copy the agent package to the machine that will be running the agent
- Extract the package
- Navigate to the extracted location
- Configure venv and python dependencies using requirements.txt
- Configure agent settings under conf.d/
- Test the agent
- Run agent with cron.py.
The final steps are described in more detail below:
- Configure venv and python dependencies:
- The configure_python.sh script sets up a virtual python environment and installs all required libraries for running the agent.
- ./setup/configure_python.sh
- The configure_python.sh script sets up a virtual python environment and installs all required libraries for running the agent.
- Agent configuration:
- The config.ini file contains all of the configuration settings needed to connect to the Elasticsearch instance and to stream the data to InsightFinder.
- Populate all of the necessary fields in the config.ini file with the relevant data. More details about each field can be found in the comments of the config.ini file and the Config Variables below.
- Test the agent:
- Once you have finished configuring the config.ini file, you can test the agent to validate the settings.
- This will connect to the Elasticsearch instance, but it will not send any data to InsightFinder. This allows you to verify that you are getting data from Elasticsearch and that there are no failing exceptions in the agent configuration.
- User -p to define max processes, use –timeout to define max timeout.
- ./setup/test_agent.sh
- Run agent with cron:
- For the agent to run continuously, it will need to run as a cron job with cron.py. Every config file will start a cron job.
- nohup venv/bin/python3 cron.py &
- For the agent to run continuously, it will need to run as a cron job with cron.py. Every config file will start a cron job.
- Stopping the agent:
- Once the cron is running, you can stop the agent by kill the cron.py process.
# get pid of background jobs
jobs -l
# kill the cron process
kill -9 PID
Using InsightFinder UI to Generate Agent Configuration
To generate the config file using InsightFinder UI, in the settings for the Elasticsearch project, go to ‘Data Collection’ under ‘Advanced Settings’.
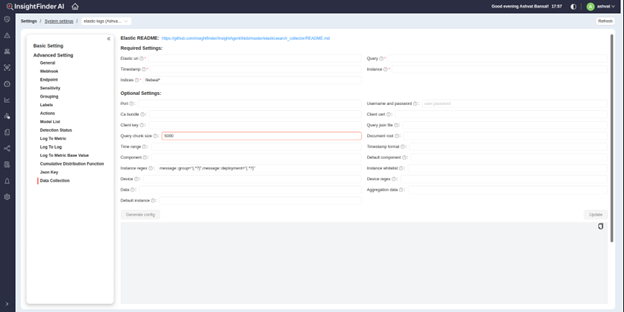
- Users can enter the respective details here to generate any configuration required to send any data from Elasticsearch to InsightFinder, using the tooltips to understand the requirement for each entry.
- Once all the settings needed to be configured are entered, click on ‘Generate Config’ to generate a new configuration file for the elasticsearch_collector. If users also want to save these settings, click on ‘Update’ in bottom right, and the settings will be saved for future reference.
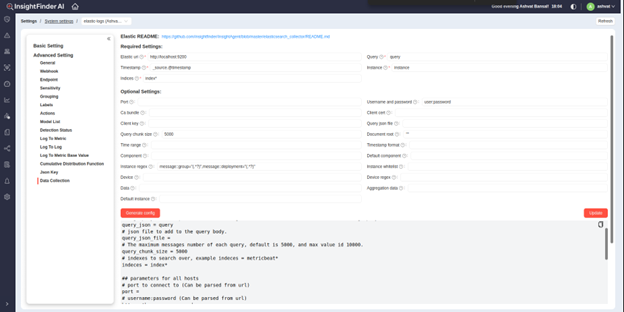
- The generated file can now be used by elasticsearch_collectors when placed in the conf.d/ directory of the collector as config.ini.
Configuration File Variables in Detail
This section explains all the configuration file variables and their purpose if users want to achieve a specific use case or scenario and utilize all the capabilities that the elasticsearch_collector offers
ElasticSearch Settings
- es_uris: A comma delimited list of RFC-1738 formatted urls. (Required)
- Example: <scheme>://[<username>:<password>@]hostname:port
- Username and Password are optional above, and can be provided below as well
- query_json: Query in json format for elasticsearch. (Optional*)
- Not needed if providing a json file for query
- query_json_file: Json file to add to query body. (Optional*)
- Not needed if providing query_json above
- query_chunk_size: The maximum number of messages for each query.
- Default is 5000, max is 10000.
- indeces: Indeces to search over. (Required)
- can list multiple indeces separated by comma
- Regex/wildcards supported
- query_time_offset_seconds: The time offset when querying live data w.r.t current time
- Default is 0
- port: Port to connect to where ElasticSearch is running. (Optional)
- Overridden if port provided in URL
- http_auth: username:password used to connect to ElasticSearch. (Optional)
- Overridden if provided in the URL
- use_ssl: True or False if SSL should be used. (Optional)
- Overridden if URI scheme is https
- ssl_version: Version of SSL to use. (Optional)
- Accepted values: SSLv23 (default), SSLv2, SSLv3, TLSv1
- ssl_assert_hostname: True or False if hostname verification should be enabled. (Optional)
- ssl_assert_fingerprint: True or False if fingerprint verification should be enabled. (Optional)
- verify_certs: True or False if certificates should be verified. (Optional)
- ca_certs: Path to CA bundle. (Optional)
- client_cert: Path to client certificate. (Optional)
- client_key: Path to client key. (Optional)
- his_time_range: Historical data time range. (Optional)
- If this option is set, the agent will query metric values by time range.
- Example: 2020-04-14 00:00:00,2020-04-15 00:00:00
- project_field: Field name in response for the project name. (Optional)
- If this field is empty, the agent will use project_name in the insightfinder section.
- project_whitelist: Regex string used to define which projects form project_field will be filtered. (Optional)
- timestamp_format: Format of the timestamp, in python arrow. If the timestamp is in Unix epoch, this can be set to epoch.
- If the timestamp is split over multiple fields, curlies can be used to indicate formatting, ie: YYYY-MM-DD HH:mm:ss ZZ
- If the timestamp can be in one of multiple fields, a priority list of field names can be given: timestamp1,timestamp2.
- timezone: Timezone of the timestamp data stored in/returned by the DB. (Optional)
- Note: if timezone information is not included in the data returned by the DB, then this field has to be specified.
- timestamp_field: Field name for the timestamp. (Required)
- Default is @timestamp.
- If document_root_field is “”, then need to set the full path. For example _source.@timestamp
- target_timestamp_timezone: Timezone of the timestamp data to be sent and stored in InsightFinder.
- Default value is UTC
- Only if you wish to store data with a time zone other than UTC, this field should be specified to be the desired time zone.
- document_root_field: Defines the root for fields below. (Optional)
- Default is _source
- To use the whole document as the root, use “”
- component_field: Field name for the component name. (Optional)
- default_component_name: Default component name if component_field is not set or field value is empty. (Optional)
- instance_field: Field name for the instance name. (Optional)
- If no value is given, the elasticsearch’s server name will be used.
- instance_field_regex: Field name and regex for the instance name. (Optional)
- If no match or empty, will use instance_field setting
- instance_whitelist: This field is a regex string used to define which instances will be filtered. (Optional)
- default_instance_name: Default instance name if not set/found from above. (Optional)
- device_field: Field name for the device/container for containerized projects.
- Can be set as a priority list: device1,device2.
- If document_root_field is “”, need to set the full path. For example _source.device
- device_field_regex: Regex to retrieve the device name using a capture group named ‘device’. (Optional)
- Example: ‘(?P<device>.*)’
- data_fields: Comma-delimited list of field names to use as data fields. (Optional)
- Each data field can either be a field name (name) or regex.
- If it is empty, the whole document at the document root will be sent.
- Example: Example: data_fields = /^system\.filesystem.*/,system.process.cgroup.memory.memsw.events.max
- aggregation_data_fields: Fields to aggregate in query/response, string or regex separated by commas. (Optional)
- Example: /0-metric\.values\.99.0/,value,doc_count
- agent_http_proxy: HTTP proxy used to connect to the agent. (Optional)
- agent_https_proxy: HTTPS proxy used to connect to the agent. (Optional)
InsightFinder Settings
- user_name: User name in InsightFinder. (Required)
- license_key: License Key from your Account Profile in the InsightFinder UI. (Required)
- project_name: Name of the project created in the InsightFinder UI. (Required)
- If this project does not exist, the agent will create it automatically.
- system_name: Name of System owning the project. (Required)
- If system_name does not exist in InsightFinder, the agent will create a new system automatically from this field or project_name.
- project_type: Type of the project (Required)
- Accepted Values: metric, metricreplay, log, logreplay, incident, incidentreplay, alert, alertreplay, deployment, deploymentreplay.
- containerize: Set to YES if project is a container project. (Required)
- Default: no
- enable_holistic_model: Enable holistic model when auto creating project. (Optional)
- The default is false.
- sampling_interval: How frequently (in Minutes) data is collected. Should match the interval used in project settings. (Required)
- Default is 10
- frequency_sampling_interval: How frequently (in Minutes) the hot/cold events are detected.
- Default value is 10
- log_compression_interval: How frequently (in Minutes) the log messages are compressed. (Optional)
- Default value: 1
- enable_log_rotation: Enable/Disable daily log rotation. (Optional)
- True or False
- log_backup_count: The number of the log files to keep when enable_log_rotation is true. (Optional)
- run_interval: How frequently (in Minutes) the agent is run. (Required)
- Should match the interval used in cron.
- Default value: 10
- worker_timeout: Timeout (in Minutes) for the worker process. (Optional)
- The default is the same as run_interval.
- chunk_size_kb: Size of chunks (in KB) to send to InsightFinder. (Optional)
- The default is 2048.
- if_url: URL for InsightFinder. (Required)
- Default is https://app.insightfinder.com.
- if_http_proxy: HTTP proxy used to connect to InsightFinder. (Optional)
- if_https_proxy: HTTPS proxy used to connect to InsightFinder. (Optional)
